
There are a lot of social websites (Facebook, Twitter, etc), messengers and applications that support various languages in which we can write. In order to process these texts, one must identify the language of the text before further processing or performing machine translation (translating text from one language to other). Language identification is formulated as a supervised machine learning task of mapping a text to a unique language from a set of trained languages. It involves building language models from a lot of text data of respective languages and then identifying the test data (text) among the trained language models. So, lets get started with building the language models.
In this blog-post, we will build bi-gram language models from training text data. A bi-gram is a contiguous 2-character slice of a word. A sentence is group of words with spaces. We also consider spaces as a character of the bi-grams in order to mark the distinction between beginning/end of word and the inner bi-grams. For example, a sentence “he eats” will have following bi-grams.
_h, he, e_, _e, ea, at, ts, s_
Text sentences of a language are tokenized (in characters), surrounded with spaces or underscores. From these tokens, bi-grams are generated and their occurrences are counted. The list of bi-grams is sorted in descending order of their frequencies and the most frequent ones produce the bi-gram language model from training corpus. While testing the text sentence, a bi-gram list of the sentence is generated and the frequencies of each bi-gram is summed up for a language model. Language with maximal sum is chosen as language of the text sentence. Having said that, we will walk through the following steps to demonstrate the experiment and its accuracy.
- Build bi-gram model for 6 languages. The training corpus consists of 30000 sentences from news/web domain.
- Test the language model on the test corpus (10000 unseen sentences from news/web domain) of these 6 languages downloaded from the same text corpus.
- Test the language model on pre-processed tweets of these 6 languages.
Both the training and test corpus have been archived and can be downloaded from here. The original source of the text corpus is wortschatz leipzig corpora. Also, the chosen six languages were such that the same languages are present in the LIGA twitter dataset which consists of 9066 tweets. The six languages chosen are German, English, Spanish, French, Italian and Dutch.
1. Building Bi-gram Language model
a) Natural Language Toolkit (NLTK/Python)
Bi-gram language model is created for each of the six languages. Finding bi-grams and their frequencies will be achieved through NLTK (Natural language toolkit) in Python. NLTK is a popular open source toolkit, developed in Python for performing various tasks in text processing (aka natural language processing). If you have installed Anaconda (3rd party distribution for Python) then NLTK comes bundled with it. Further, you will have to install NLTK data using an interactive installer (link) which appears when you execute the code nltk.download() after importing nltk by writing import nltk.
b) Pre-processing the text corpus
Pre-processing of text for language identification task simply aims to remove texts which are language independent/deteriorating entities and incorporate the logic which can enhance the accuracy of the identification task. We have considered the following pre-processing steps before creating bi-gram language model.
- All the texts were converted to lower case.
- All the digits were removed from the text sentences.
- Punctuation marks and special characters were removed.
- All the sentences were concatenated with space in between.
- Series of contiguous white spaces were replaced by single space.
It is important to note that the text file must be read in Unicode format (UTF-8 encoding) which encompasses the character set including all the languages. ASCII encoding is not sufficient as it only covers the English language’s character set. The Python code for above mentioned steps can be seen in next section.
c) Bi-gram extraction and Language model
Now, we will use library functions of NLTK to find out list of bi-grams sorted with number of occurrences for each language. The following code snippet shows how we can extract sorted bi-grams and their frequencies from tokenized sequence of characters (list of characters sequence formed from 30,000 text sentences of a language) using NLTK.
finder = BigramCollocationFinder.from_words(seq_all) finder.apply_freq_filter(5) bigram_model = finder.ngram_fd.viewitems() bigram_model = sorted(finder.ngram_fd.viewitems(), key = lambda item : item[1], reverse = True)
apply_freq_filter(5) removes all the bi-grams which have frequencies less than 5 as they might not be a relevant bi-gram of the language. sorted() functions sorts the bi-gram list in descending order of their frequencies. The full Python implementation of building a language model from text corpus using NLTK is given below.
from nltk.collocations import BigramCollocationFinder
import re
import codecs
import numpy as np
import string
def train_language(path,lang_name):
words_all = []
translate_table = dict((ord(char), None) for char in string.punctuation)
# reading the file in unicode format using codecs library
with codecs.open(path,"r","utf-8") as filep:
for i,line in enumerate(filep):
# extracting the text sentence from each line
line = " ".join(line.split()[1:])
line = line.lower() # to lower case
line = re.sub(r"\d+", "", line) # remove digits
if len(line) != 0:
line = line.translate(translate_table) # remove punctuations
words_all += line
words_all.append(" ") # append sentences with space
all_str = ''.join(words_all)
all_str = re.sub(' +',' ',all_str) # replace series of spaces with single space
seq_all = [i for i in all_str]
# extracting the bi-grams and sorting them according to their frequencies
finder = BigramCollocationFinder.from_words(seq_all)
finder.apply_freq_filter(5)
bigram_model = finder.ngram_fd.viewitems()
bigram_model = sorted(finder.ngram_fd.viewitems(), key=lambda item: item[1],reverse=True)
print bigram_model
np.save(lang_name+".npy",bigram_model) # save language model
if __name__ == "__main__":
root = "train\\"
lang_name = ["french","english","german","italian","dutch","spanish"]
train_lang_path = ["fra_news_2010_30K-text\\fra_news_2010_30K-sentences.txt","eng_news_2015_30K\\eng_news_2015_30K-sentences.txt","deu_news_2015_30K\\deu_news_2015_30K-sentences.txt","ita_news_2010_30K-text\\ita_news_2010_30K-sentences.txt","nld_wikipedia_2016_30K\\nld_wikipedia_2016_30K-sentences.txt","spa_news_2011_30K\\spa_news_2011_30K-sentences.txt"]
for i,p in enumerate(train_lang_path):
train_language(root+p,lang_name[i])
As you can see, the above code includes all the steps of pre-processing and creating the bi-gram language model of each language in train directory. I hope that comments in the code are self explanatory.
2. Evaluation on Test Corpus
Test corpus contains nearly 10,000 sentences per language. To classify a text sentence among the language models, the distance of the input sentence is calculated with the bi-gram language model. The language with the minimal distance is chosen as the language of the input sentence. Once the pre-processing of the input sentence is done, the bi-grams are extracted from the input sentence. Now, the frequencies of each of these bi-grams are calculated from the language model and are summed up. The summed up frequency value for each language is normalized by sum of frequencies of all the bi-grams in the respective language. This normalization is necessary in order to remove any bias due to size of the training text corpus of each language. Also, we have multiplied the frequencies by a factor of 10,000 to avoid the case when normalized frequency (f/total[i]) become zero. The equation for the above mentioned calculation is given below(where is equation).

, where 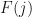
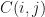
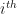



The full implementation of closed set evaluation of language identification task on wortschatz test corpus is given below. tp and fp are true positives and false positives respectively. True positives are number of sentences which are detected correctly and false positives are number of sentences which were wrongly detected as some other language.
from nltk.collocations import BigramCollocationFinder
import re
import codecs
import numpy as np
import string
def test_language(path,language,total):
tp = 0
fp = 0
lang_name = ["english","german","french","italian","dutch","spanish"]
model = [np.load(lang+".npy") for lang in lang_name]
with codecs.open(path,"r","utf-8") as filep:
translate_table = dict((ord(char), None) for char in string.punctuation)
for l,line in enumerate(filep):
line = " ".join(line.split()[1:])
line = line.lower()
line = re.sub(r"\d+", "", line)
line = line.translate(translate_table)
finder = BigramCollocationFinder.from_words(line)
freq_sum = np.zeros(6)
for k,v in finder.ngram_fd.items():
isthere = 0
for i,lang in enumerate(lang_name):
for key,f in model[i]:
if k == key:
freq_sum[i] = freq_sum[i]+(f*10000)/total[i]
isthere = 1
break
if isthere == 0:
freq_sum[i] = freq_sum[i] + 1
max_val = freq_sum.max()
index= freq_sum.argmax()
if max_val != 0:
if lang_name[index] == language:
tp = tp + 1
else:
fp = fp + 1
print "tp = ",tp,"fp = ",fp,freq_sum
print "True Positive = ",tp
print "False Positive = ",fp
if __name__ == "__main__":
root = "test\\"
lang_name = ["english","german","french","italian","dutch","spanish"]
no_of_bigms = []
for i,lang in enumerate(lang_name):
model = np.load(lang+".npy")
total = 0
for key,v in model:
total = total + v
no_of_bigms.append(total)
print total
train_lang_path = ["eng_news_2015_10K\\eng_news_2015_10K-sentences.txt","deu_news_2015_10K\\deu_news_2015_10K-sentences.txt","fra_news_2010_10K-text\\fra_news_2010_10K-sentences.txt","ita_news_2010_10K-text\\ita_news_2010_10K-sentences.txt","nld_wikipedia_2016_10K\\nld_wikipedia_2016_10K-sentences.txt","spa_news_2011_10K\\spa_news_2011_10K-sentences.txt"]
for i,p in enumerate(train_lang_path):
print "Testing of ",lang_name[i]
test_language(root+p,lang_name[i],no_of_bigms)
Hope you have followed the blog-post conveniently till here. I would advice the readers to make sure that the file paths are correct while executing the codes on their systems. The evaluation time will be more as the complexity of the code is high and sequential. So, have patience.
Results
The results of the evaluation on 10,000 unseen sentences of each languages from news domain have been shown below in form of confusion matrix.
| Languages | English | German | French | Italian | Dutch | Spanish |
| English | 9244 | 38 | 199 | 145 | 222 | 139 |
| German | 28 | 9514 | 67 | 29 | 325 | 27 |
| French | 20 | 52 | 9525 | 165 | 83 | 160 |
| Italian | 6 | 7 | 18 | 9822 | 16 | 134 |
| Dutch | 60 | 66 | 35 | 20 | 9800 | 19 |
| Spanish | 6 | 8 | 41 | 242 | 24 | 9679 |
3. Evaluation on LIGA Twitter dataset
LIGA dataset contains 9066 pre-processed and cleaned tweets. I have tested these tweets against the language models created earlier. One does not need to do any pre-processing as these tweets are already clean. The evaluation code for Twitter dataset has been left for readers to write as it will be similar to the evaluation code shown earlier for test corpus. Similar to confusion matrix of test corpus, confusion matrix for LIGA dataset has been shown below.
| Languages | English | German | French | Italian | Dutch | Spanish |
| English | 1177 | 27 | 96 | 37 | 94 | 74 |
| German | 18 | 1245 | 31 | 17 | 159 | 9 |
| French | 7 | 15 | 1421 | 42 | 19 | 47 |
| Italian | 5 | 3 | 7 | 1484 | 4 | 36 |
| Dutch | 11 | 27 | 6 | 10 | 1371 | 5 |
| Spanish | 2 | 8 | 20 | 57 | 16 | 1459 |
One obvious question that may arise in your mind would be “How to clean the tweets which are in the raw form”. For that, you can perform following pre-processing steps before actually feeding it into language identification task (either training or testing).
# To remove web links(http or https) from the tweet text
tweet_text = re.sub(r"http\S+", "", tweet_text)
# To remove hashtags (trend) from the tweet text
tweet_text = re.sub(r"#\S+", "", tweet_text)
# To remove user tags from tweet text
tweet_text = re.sub(r"@\S+", "", tweet_text)
# To remove re-tweet "RT"
tweet_text = re.sub(r"RT", "", tweet_text)
# To remove digits in the tweets
tweet_text = re.sub(r"\d+", "", tweet_text)
# To remove new line character if any
tweet_text = tweet_text.replace('\\n','')
# To remove punctuation marks from the tweet
translate_table = dict((ord(char), None) for char in string.punctuation)
tweet_text = tweet_text.translate(translate_table)
# To convert text in lower case characters(case is language independent)
tweet_text = tweet_text.lower()
These pre-processing steps can be included in the training or evaluation code if you are using raw twitter data-sets for some application. The mentioned entities (comments) in the above code are independent of text language and will deteriorate bi-gram language model.
Concluding Remarks
Hope the blog-post helps in understanding the n-gram approach used for language detection task. Also, you can easily reproduce the results once you have followed the post till here. For more inquisitive ML enthusiasts, there are few areas which can be worked upon in order to improve the accuracy of the system further, like
- Size of training set – Larger training corpus will lead to calculation of accurate statistics (frequency counts) of bi-grams in the language. One can create the language models on 1 million sentences downloaded from wortschatz leipzig corpus.
- There are lots of named entities (proper nouns) in the text sentence which degrade the language model as these names are always language independent. In my opinion, accuracy of detection task will increase if we are able to remove such words.
- In the followed approach of n-gram models, we have created models with n = 2. Accuracy achieved in the evaluation process will certainly increase as n = 3 or 4 (tri-grams and quad-grams) will be used.
One can find various other ways of performing language detection task in literature. Readers are encouraged to study and implement following approaches:
1. Combining n-gram language models with Naive Bayes classifier.
2. Combining n-grams language models with rank order statistics classifier to calculate “out-of-place measure” of n-grams in a document.
The full implementation of followed approach and evaluation code for both test corpus and LIGA twitter data-set can be downloaded from GitHub link here.
If you liked the post, follow this blog to get updates about upcoming articles. Also, share it so that it can reach out to the readers who can actually gain from this. Please feel free to discuss anything regarding the post. I would love to hear feedback from you.
Happy machine learning 🙂

Traceback (most recent call last):
File “langdetect.py”, line 68, in
model = np.load(lang+”.npy”)
File “/home/hasna/.local/lib/python2.7/site-packages/numpy/lib/npyio.py”, line 370, in load
fid = open(file, “rb”)
LikeLike
You will have to train the language model first.
I would advise you to go through the blog one by one in order to understand the approach.
First you have to train the language models on the training data
Then you can perform evaluation of test corpus.
You will find download links of train and test corpus in the blog.
LikeLike
Hello, thanks for tutorials. I try copy your code but error on ‘FreqDist’ object has no attribute ‘viewitems’ . I try viewitems() to items() and it run successfully
LikeLiked by 1 person
Probably NLTK version would be different.
LikeLike
Hello, thanks for tutorials. I try copy your code but error on ‘FreqDist’ object has no attribute ‘viewitems’ . I try viewitems() to items() and it run successfully
LikeLike
Why have you multiplied the frequencies by a factor of 10,000?
You said its to avoid the case when normalized frequency (f/total[i]) become zero, but if normalized freq is 0, multiplying it with 10000 should also be Zero.
LikeLike